
얼마전 좋아요 기능을 만들고, 성능 개선을 위해 Redis를 도입했습니다. 이 방식이 실제로 성능 개선이 되는지? 얼마나 개선되었는지? 테스트를 해보기로 했습니다.
스트레스, 부하, 성능 테스트
이 테스트들은 비슷한 말 같지만 목적이 다릅니다.
스트레스 테스트
- 서버에 한계 이상의 트래픽을 주어 시스템의 한계를 확인하는 것이 목표입니다.
- 서버에 폭발적인 트래픽이 오는 상황에서 어떻게 동작하는지 확인해볼 수 있습니다.
- 과부하가 일어나고 오류들이 잘 복구되는지, 알림이 잘 오는지 등을 확인할 수 있습니다.
부하 테스트
- 서버에 적당히 큰 트래픽을 주며 장시간 서비스가 가능한지 내구성 테스트를 하는 것이 목표입니다.
- thread 문제, 메모리 누수, 로드벨런싱 실패 등 여러 문제가 발생할 수 있습니다.
- 주로 이런 지속적인 운영 관점에서의 테스트를 진행합니다.
성능 테스트
- 서버가 특정 상황에서 얼마나 요청들을 잘 처리하는지 확인하는 것이 목표입니다.
- 평균 응답 속도, 처리량, 리소스 사용량 등과 같이 성능을 중점적으로 확인합니다.
크게 보면 부하 테스트를 성능 테스트의 하위 개념으로 볼 수도 있을 것 같네요. 이 용어들이 모두 다르게 쓰이긴 하지만, 엄격한 구분은 없는 듯 합니다. 많은 곳에서 차이를 설명하지만 말이 조금씩 달라요. 개념의 엄격한 정의가 중요한건 아닌 것 같아요.
이 글에서는 성능 테스트에 중점을 둘 예정입니다.
nGrinder
네이버에서 유지보수하고 있는 오픈소스 프로젝트입니다. Github
몇 가지 특징이 있습니다.
- 웹 기반으로 테스트를 진행할 수 있어서 별도의 툴을 설치하지 않아도 됩니다. (서버 제외)
- Jython, Groovy 스크립트를 기반으로 테스트를 작성합니다.
- IDE의 지원을 받으며 스크립트를 작성할 수도 있습니다.
- 에이전트가 실제로 요청을 보내는데, 이 에이전트를 여러 개 사용할 수 있습니다. 심지어 agent 분산 환경을 구성해서 요청을 보낼 수도 있습니다.
비슷하게 jMeter도 성능 테스트 도구입니다. 그런데 제가 nGrinder를 선택한 두 가지 이유가 있어요.
- 스크립트를 통한 자동화 테스트 가능. 이게 좀 큰 매력 포인트입니다. 스크립트를 사용해서 유연한 테스트가 가능합니다. jMeter도 어떻게든 가능하긴 하지만 레퍼런스도 거의 없고 사용하기 어렵습니다.
- Agent 기반의 요청 테스트. 다양한 네트워크 환경에 있는 agent를 사용해서 더 사실적인 테스트를 진행해볼 수 있습니다. 물론 인프라와 셋팅이 필요하긴 합니다.
동작 방식
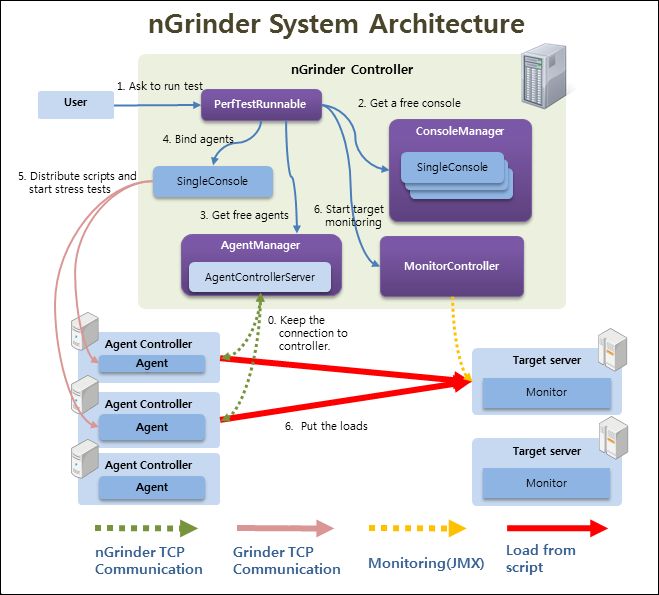
nGrinder Controller는 테스트하기 쉽게 Web Interface를 제공합니다. 저희는 이 web interface를 통해 테스트를 요청할 수 있습니다. 그리고 script를 짤 수 있는 환경도 제공합니다.
Agent는 실제 요청을 보내는 process입니다. Controller를 통해서 테스트를 요청하면 controller가 agent에게 스크립트와 함께 요청을 보냅니다. 하나의 Controller에 여러 agent가 붙을 수 있습니다. 심지어 다른 컴퓨터의 controller에 agent가 붙을 수도 있습니다.
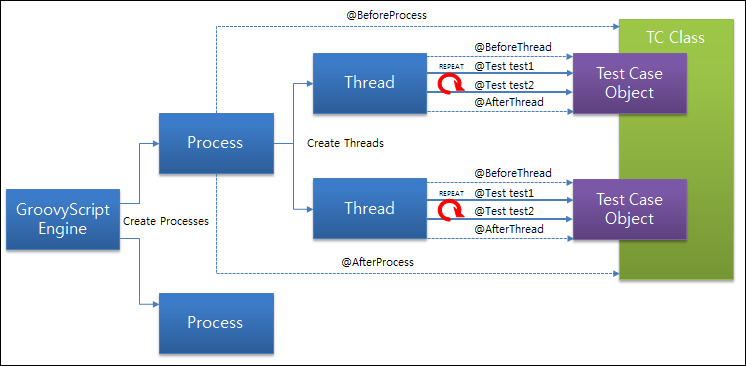
Agent는 스크립트를 실행할 때 process와 thread를 여러 개 만들어서 요청을 보냅니다. 위와 같은 구조로 n개의 process와 n*m개의 thread를 만들어 테스트합니다.
실제 성능 테스트를 진행할 때 process와 thread 수를 지정하는데요. 이때 주의할 점은 thread는 총 개수가 아니라 process당 thread 개수입니다. 그래서 3개의 process, 10개의 thread로 지정하면 총 30개의 thread가 생성됩니다.
생성된 각 thread는 테스트 케이스를 실행합니다. 1번만 실행하지않고 지정한 만큼 계속 실행합니다. 그래서 자원 할당에 신경을 쓰면서 테스트를 짜야합니다. 기본적으로 thread들 끼리 자원 공유를 하고자한다면 전역 변수를 사용하면 됩니다. 저희는 Groovy 스크립트를 사용할 겁니다. nGrinder는 groovy에 자원 할당, 해제와 관련해서 여러 편의 annotation들을 제공합니다.
| Annotation | 설명 | 메서드 타입 | 용도 |
|---|---|---|---|
| @BeforeProcess | Process 시작전 호출할 함수를 지정 | static | Thread간 공유되어야할 자원들을 부르는 로직. GTest와 관련된 코드들을 호출하는 로직 |
| @AfterProcess | Process가 종료되고 호출할 함수 지정 | static | 자원 할당 해제 |
| @BeforeThread | Thread 시작 전 호출할 함수를 지정 | member | 로그인하는 로직. Cookie 설정 등과 같이 Thread별로 수행되어야하는 로직. |
| @AfterThread | Thread가 종료되고 호출할 함수 지정 | member | 로그아웃하는 로직 |
| @Before | 각 @Test 실행 전에 호출할 함수 지정 | member | @Test끼리 공유하는 공통 로직을 묶는 용도 |
그 외 자세한 내용은 여기에서 확인해보세요.
좋아요에 Redis 도입
위의 글은 좋아요 기능에 Redis를 도입해서 어떻게 성능을 향상시켰는지에 관한 글입니다.
간단하게 요약하면 '좋아요 데이터 영구 저장은 DB에 하되, Redis에 캐싱해서 사용하자' 입니다.
좋아요 기능 호출 순서
좋아요 기능은 로그인한 사용자만 누를 수 있습니다. 왜냐하면 한 사람당 1번만 눌러야 하기 때문이에요. 그래서 요청 순서는 아래와 같습니다.
- 로그인 요청
- 특정 Post에 좋아요 요청
미리 User 준비
좋아요는 한 User당 1회만 누를 수 있기 때문에 User를 미리 많이 준비해두어야 합니다. 물론 성능 테스트만 하면 되니까 내부 로직을 좀 수정해서 여러 번 누를 수 있게 바꿔도 됩니다. 하지만 이렇게 하면 코드 수정이 필요해서 번거로워집니다. 그래서 저는 그냥 User를 4000개 만들어서 테스트하기로 했습니다.
Java를 활용해 Insert문을 자동 생성해주는 코드를 짜서 SQL을 만들었습니다.
1
2
3
4
5
6
7
StringBuilder sqlContent = new StringBuilder();
for (int i = 1; i <= 4000; i++) {
String name = "홍길동" + i;
String sql = String.format("INSERT INTO app_user values (%d, %s, 1111%04d, 010-1111-%04d, ROLE_USER, ACTIVE)", i, name, i, i);
sqlContent.append(sql);
}
System.out.println(sqlContent.toString()); // SQL 출력
좋아요 요청 Script 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
import groovy.json.JsonSlurper
import net.grinder.plugin.http.HTTPPluginControl
import net.grinder.script.GTest
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPResponse
import java.nio.charset.StandardCharsets
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.assertEquals
@RunWith(GrinderRunner)
class Like {
public static GTest test
public static HTTPRequest request
public Map<String, String> headers = [:] // 토큰 인증 방식을 위해 accessToken header 저장
@BeforeProcess
public static void beforeProcess() {
test = new GTest(1, "DB Like")
request = new HTTPRequest()
test.record(request)
}
@BeforeThread
public void beforeThread() {
grinder.statistics.delayReports = true;
// 랜덤 ID로 로그인 요청
int rand = new Random().nextInt(4000)
String body = String.format("{\"id\": \"1111%04d\", \"password\": \"121212\"}", rand)
HTTPResponse res = request.POST("http://localhost:8080/user/login", body.getBytes(StandardCharsets.UTF_8))
// 로그인 요청후 받은 응답에서 accessToken 추출
def text = res.getBodyText(StandardCharsets.UTF_8)
def json = new JsonSlurper().parseText(text)
headers.clear()
headers.put("Content-Type", "application/json")
headers.put("Authorization", "Bearer " + json.accessToken)
}
@Test
public void test() {
// 1234번 글에 like 요청
// [:]는 빈 Map 생성
HTTPResponse response = request.POST("http://localhost:8080/post/like/1234", [:], headers)
// 요청 성공했는지 확인
assertEquals("{\"message\":\"ok\"}", response.getBodyText().replaceAll("\\s", ""))
assertEquals(200, response.statusCode)
}
}
Groovy는 전반적으로 Java와 비슷해서 사용하기 편합니다. 코드 구성을 보시면 JUnit 스타일이죠? 성능 테스트에 필요한 요청을 마치 테스트처럼 구현합니다.
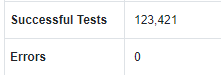
그래서 테스트 성공은 요청 성공, 테스트 실패는 요청 실패로 간주해요. 이건 나중에 통계에서 요청 성공, 실패 개수를 확인할 수 있습니다.
GTest
GTest 는 테스트 통계에 사용되는 클래스입니다. 프로세스 전반에 걸쳐 공유해서 사용하므로 @BeforeProcess에서 초기화를 해주어야 해요.
초기화 해주면서 request를 만들어주고 이 request를 GTest에 넘겨주어야 합니다. 그러면 request를 통해서 외부 API를 호출할 때, 호출 정보(걸린 시간, 응답 등)을 GTest에 통계로 저장합니다.
로그인
각 thread 1개는 1명의 user를 표현합니다. 그래서 로그인은 매 thread마다 해주어야합니다. 만약 매 test마다 로그인이 필요하다면 @Before나 로그인이 필요한 @Test안에 구현해주시면 됩니다.
로그인 과정은 이렇습니다.
- post방식으로 로그인 API 요청을 보냅니다.
- 받은 Json응답을 파싱하고, accessToken을 추출해서 headers에 담아둡니다.
로그인 요청을 보낼 때는 직접 Json을 만들어서 byte[]로 변환한 뒤에 보내줍니다. 변환할 때는 UTF-8방식을 사용합니다. 요청을 json타입으로 보낼 것이므로 header에 content-type도 추가해주면 좋습니다.
그리고 받은 Json 응답은 JsonSlurper를 사용해서 쉽게 파싱할 수 있습니다. 특이하게도 groovy에서는 js처럼 Map타입을 아래와 같이 조회할 수 있습니다. 그래서 json.accessToken과 같이 편리하게 원하는 값을 탐색할 수 있습니다.
1
2
json["accessToken"]
json.accessToken
좋아요 API 요청
좋아요 API도 마찬가지로 request를 통해 요청하면 됩니다. request로 POST요청을 보내면서, 아까 로그인한 정보도 header에 실어서 보내줍니다. 코드에 2번째 인자에 [:]이 있는데 이건 빈 Map을 만드는 문법입니다. 원래 param을 넣는 인자지만 넣을 param이 없기 때문에 빈 map을 넣었습니다.
요청을 보내고 받은 응답에 assert를 달아서 성공한 요청인지 판단합니다. 200번 status code인지, 응답이 {"message": "ok"}인지 테스트합니다. 저는 json 응답이 단순해서 문자열로 비교했지만, 응답이 복잡하면 JsonSlurper로 파싱하고 그 요소들을 assert해야 코드가 깔끔할겁니다.
이 Script는 어디에 저장하죠?
nGrinder 페이지(기본 localhost:8300) 로 가서 Script에 만들어 주면 됩니다.
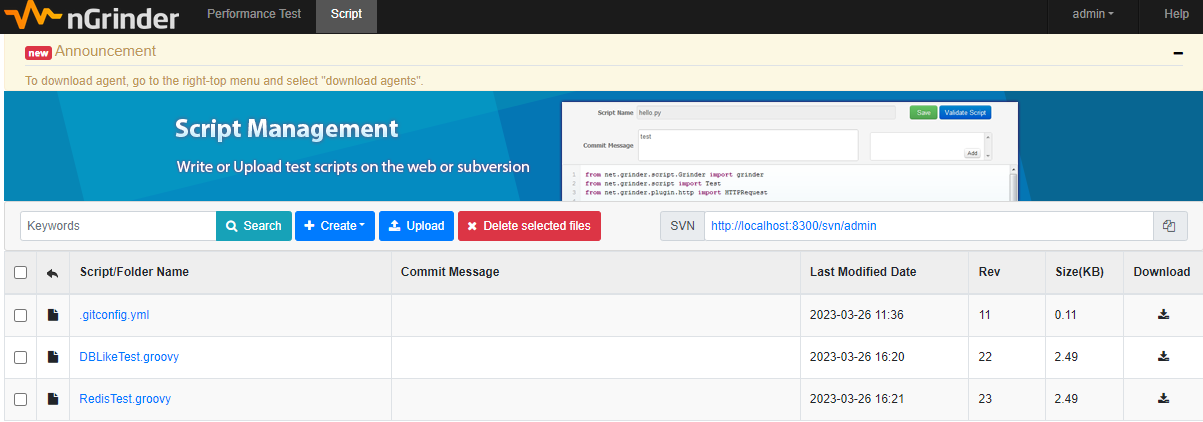
Create - Create a script 버튼을 누르고, Script Name만 입력해줘도 됩니다. 아래 URL까지 적어주면 생성되는 sample code에 그 url을 자동으로 넣어주긴 합니다.
테스트 생성
이제 모든 준비가 끝났고, 실제로 테스트를 해보면 됩니다. Performance Test - Create Test를 눌러주시고 테스트 정보들을 기입해주세요.

그리고 아래와 같이 테스트 기본 설정을 해주시면 됩니다.
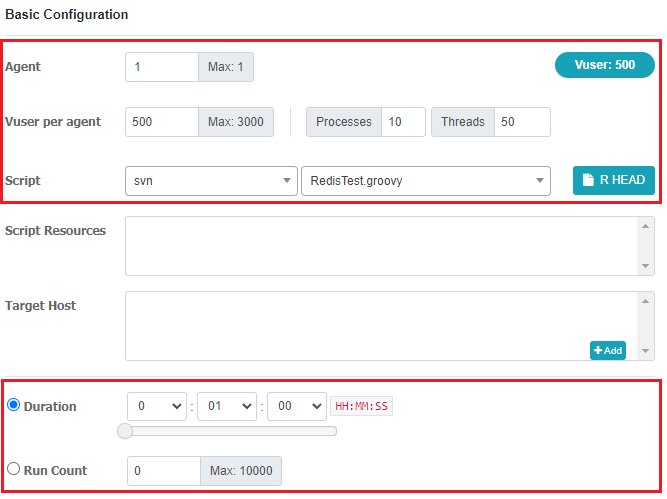
빨간색 박스 부분이 중요한 부분입니다.
Agent는 사용할 Agent개수입니다. 저는 가볍게 1개만 등록해서 사용했습니다.Vuser per agent는 사용할 process와 thread를 정하는 부분입니다. process는 그대로 만들어지고, thread는 process별 thread개수입니다. 그래서 저는 총 500개의 thread가 만들어지겠네요.Vuser는 Virtual user입니다. 요청을 보내는 유저 수라는 의미입니다. 정확히는agent × processes × threads로 정의합니다. 결국 실제 생성되는 총 thread수를 의미하기도 해요.Script에는 실행할 테스트 스크립트를 넣으시면 됩니다. svn을 선택하고 아까 저장한 script파일을 선택해주세요. github도 지원하긴하는데 저는 스크립트 컴파일이 안돼서 svn을 그대로 사용했습니다. nGrinder에서 svn을 주로 사용하기때문에 svn을 사용하시는게 마음 편하실겁니다.Duration은 테스트를 진행할 시간을 의미합니다. 1분동안 요청을 계속 보내는거에요. 만약Run Count로 정확한 횟수를 지정하면 Thread별로 그 횟수만큼만 요청보냅니다. 저는 10을 지정하면 총 5000번 요청이 가겠네요.
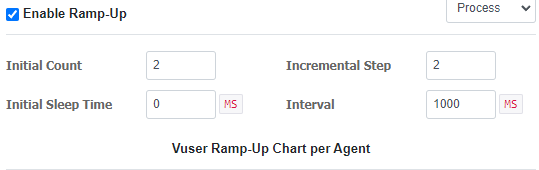
Ramp up기능도 있습니다. 이건 처음에는 요청을 조금씩 보내다가 점점 요청 수를 늘려가는 기능입니다. 부하 테스트에 유용하겠죠?
Process와 Thread를 선택하는건 기준을 선택하는겁니다. Ramp-up 설정에 넣는 수들은 모두 그 기준에 맞춰 설정됩니다. 예를 들어 Process를 선택하고 Incremental Step을 2로 사용하면, Process 기준으로 2개씩 높히겠다는 의미입니다.
테스트 진행
그리고 Save and Test를 클릭하면 실제로 테스트를 진행합니다. 테스트가 끝나면 보고서를 받아볼 수 있어요.
이 보고서에서 가장 중요한건 TPS입니다. 초당 몇 건의 transaction을 처리했는지에 관한 지표에요.
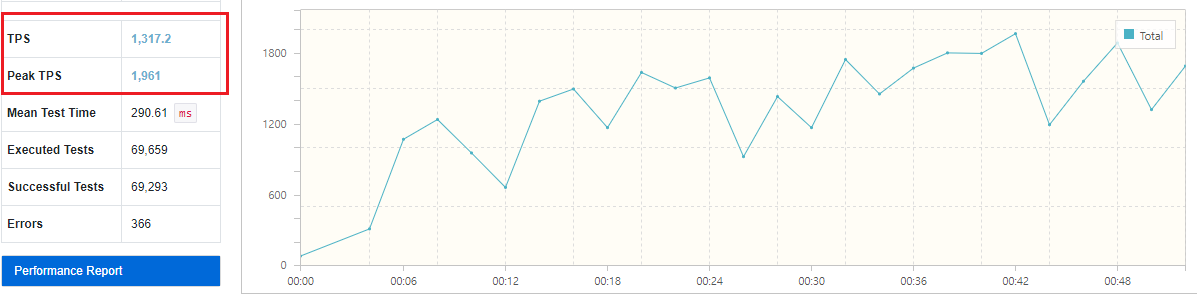
평균 1,317의 TPS가 나왔고, 최대 1,961까지 TPS가 올라갔네요.
결과에 관한 자세한 분석은 아래 글을 참고해주세요. 결론은 기존에 비해 약 86%만큼의 성능 향상이 있었습니다.
참고
- https://github.com/naver/ngrinder/wiki/Architecture
- https://github.com/naver/ngrinder/wiki/Groovy-Script-Structure