
HashMap
HashMap은 Java에서 사용하는 대표적인 Map 구현체입니다. 이름에서 알 수 있듯이 Hash를 사용해서 Key와 Value를 매핑합니다.
1
2
3
Map<Integer, String> map = new HashMap<>();
map.put(1, "HI");
System.out.println(map.get(1)); // HI
HashMap은 몇 가지 특성이 있습니다.
- key를 찾는 속도가 amortized constant time입니다. 즉 Entry set의 개수가 몇 개든 거의 동일한 속도를 보장합니다. Entry가 많아지면 resize하는 과정이 있고, 해시 충돌 등을 고려하여 amortized가 붙습니다.
- 순차적으로 저장되지 않습니다. 순서를 보장하지 않습니다.
HashMap은 어떤 방식으로 구현되어있길래 이렇게 빠른 속도로 key를 찾아낼 수 있을까요?
HashMap 간단한 동작 원리
동작 과정을 간단하게 표현하면 비교적 쉽게 이해할 수 있습니다.
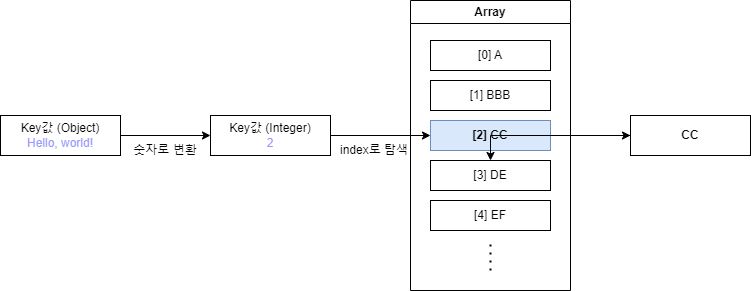
- Key값을 숫자로 매핑합니다.
- 매핑된 숫자를 index로 사용해서, 배열에서 바로 Value를 찾습니다.
이렇게 찾으면 탐색 알고리즘을 사용하지 않아도 바로 Key에 매핑된 Value를 찾을 수 있습니다.
좀 더 쉽게 다른 비슷한 예시를 들자면,
1
2
3
4
5
6
7
8
9
10
// week enum타입 정의
enum Week {
SUN, MON, TUE, WED, THU, FRI, SAT
}
// week에 매칭되는 label 정의
String[] label = {"일요일", "월요일", "화요일", "수요일", "목요일", "금요일", "토요일"};
// 탐색 알고리즘 없이 이렇게 바로 매칭되는 label을 찾을 수 있음.
System.out.println(label[Week.MON.ordinal()]); // 월요일
Week라는 enum에 매칭되는 label을 찾고싶다고 합시다. 저희는 enum타입의 ordinal을 index로 해서 label을 정의합니다. 그러면 어떤 특별한 탐색 알고리즘 없이 바로 enum에 매칭되는 label을 찾을 수 있습니다.
물론 Enum타입 자체에 label을 추가하면 문제는 더 쉽게 해결되지만, 예시를 들기 위해서 이렇게 구성해보았습니다.
하지만 여기엔 몇 가지 문제가 있습니다. 이 문제들을 해결해가면서 Hashmap의 원리를 설명하겠습니다.
Key값을 어떻게 숫자로 바꾸지?
Hashmap의 핵심입니다. Key값을 어떤 숫자로 바꾸는데, 이 숫자를 hash라고 합니다.
Object에 정의되어있는 hashCode함수를 보신적 있나요? 이 hashCode함수를 호출하면 그 Object의 hash값을 얻을 수 있습니다. 이 함수를 해시함수라고 합니다.
HashCode를 계산하는 방법은 많습니다. Integer는 그 값 자체로 hash로 사용하고, String은 문자 하나하나마다 값을 누적해서 hash를 계산합니다.
String의 hash계산
1
2
3
4
5
6
7
8
9
// StringUTF16.hashCode
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
String은 기존의 값에 31을 곱하고 문자하나 더하고… 이렇게 hash를 생성합니다.
여담으로 JDK 1.1에서는 String의 hash계산을 빠르게 하기 위해서 일정 간격의 문자들만 누적하는 방식으로 hash를 계산했다고 하네요. 이렇게 계산하면 웹 URL은 앞부분이 동일한 경우가 많은데, 이때 해시값이 동일하게 나올 확률이 높아져서 위의 방식으로 바뀌었다고 합니다.
일반적인 Object의 hash계산
대부분의 상황에서 hash를 계산할 때는 String과 유사한 방식으로 계산합니다. 예를 들어 속성이 3개인 객체가 있으면, 이 객체의 hash는 아래와 같이 구합니다.
1
2
3
4
5
6
Object attribute1, attribute2, attribute3; // 초기화했다고 가정
// 31 * hash + attribute_hashcode 와 같이 계산.
int hash = attribute1.hashCode();
hash = 31 * hash + attribute2.hashCode();
hash = 31 * hash + attribute3.hashCode();
n개면 계속 늘어나겠죠? 이 경우에는 overflow를 막기위해 나머지 연산을 이용하면 됩니다.
특히 31이란 숫자를 곱하는 이유는 몇 가지가 있는데요.
- 소수이다. 즉 해시가 겹칠 확률이 낮아진다.
- 최적화가 가능하다.
31 * i == (i << 5) - i - 전통적으로 hash계산시 31을 주로 사용한다.
위의 방식은 많이 사용되면서 어느정도 검증된 방식입니다. 해시 충돌을 최대한 줄여주고, 골고루 잘 분포되도록 설계되었어요. 물론 잘못 사용한다면 오히려 성능이 악화될 수 있으니 주의해서 사용해야합니다.
Objects클래스에 편리하게 복합 hash를 구해주는 메서드가 있긴합니다. 다만 빈번하게 사용될 경우에는 메서드 호출에 의한 overhead가 있을 수 있으니 주의해아합니다.
요즘 IDE에서는 hashCode구현을 자동으로 해주는 기능이 있으니 이걸 사용하시면 안전합니다.
그 많은 hash를 커버하려면 배열이 엄청 커야하지 않나?
Hash값의 범위는 Integer의 범위와 같죠. 이 hash를 그대로 index로 쓰려면 대략 42억개의 요소를 할당해야합니다.
1
2
ValueType[] table = new ValueType[1 << 32]; // 대략 42억개
table[key.hashCode()]; // key에 매핑된 value값 가져오기.
심지어 저 공간을 다 쓰는 것도 아니고, 요소를 2~3개만 넣는다면? 나머지 공간은 그대로 낭비됩니다.
그래서 공간을 좀 더 효율적으로 사용하기 위해서 Value 저장 공간을 M개만 만들어 둡니다. 그리고 hash를 그대로 index로 사용하지 않고, 나머지 연산을 적용해서 사용합니다.
1
int actual_index = key.hashCode() % M;
그래서 실제 인덱스는 위와 같은 형태로 사용합니다. 그런데 Hashmap에서는 이 M을 2제곱수로 사용합니다. 즉 M은 2, 4, 8, 16, …만 사용됩니다. 그래서 아래와 같이 최적화가 가능합니다.
1
2
// 비트 연산으로 바꿔 속도 향상
int actual_index = (M - 1) & key.hashCode();
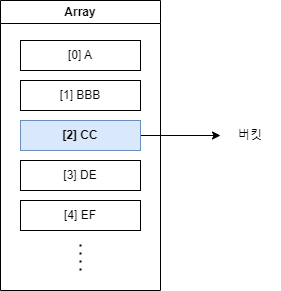
지금까지는 배열의 공간라고 표현했지만, hashmap에서는 이를 버킷이라고 부릅니다. 이제부터는 버킷이라고 부르겠습니다.
해시 값이 겹칠땐 어떻게 하나?
Hash값의 범위는 Integer의 범위죠. 즉 대략 42억개의 값까지 커버할 수 있습니다. 그러면 Long의 hash는 어떻게 될까요?
Long이 표현할 수 있는 범위는 Integer에 비해 훨씬 방대합니다. 그러면 당연히 Long의 hash를 계산했을 때, hash가 같은 값이 있을 수 밖에 없겠죠?
이뿐만 아니라 String, 다른 Object들도 마찬가지입니다. Integer보다 더 표현 범위가 넓으면, 값은 다르지만 hash가 같은 경우가 생깁니다. 이걸 해시 충돌이라고 합니다.
해시 충돌은 어쩔 수 없이 일어납니다. String은 이론상 표현할 수 있는 범위가 무한대에 가까운데, Integer는 고작 42억 정도이니까요.
그래서 HashMap에서는 Seperate Chaining 구조를 사용해서 이 문제를 해결합니다.
Seperate Chaining
이 방식은 hashmap에 어떤 entry를 넣으려고 했더니 이미 같은 hash의 키가 존재한다면?
- 그 키가 hash만 같은건지 진짜 같은건지 알 수 없습니다. 그래서 equals로 더 정교하게 비교합니다.
- 만약 진짜 같은 값이었다면, 바꿔치기합니다.
- 다른 값이라면, 버킷 끝에 추가합니다.
앞에서는 버킷에 1개의 값만 담을 수 있는 것 처럼 묘사했지만, 실제로 hashmap에서는 버킷에 여러개의 값을 담을 수 있습니다.
자바에서는 이 버킷을 기본적으로 LinkedList를 사용해서 구현합니다. 그래서 만약 최악의 경우에 넣은 모든 값의 hash가 동일하다면? 성능은 LinkedList와 동일하게 O(n)이 되어버립니다. 그래서 해시 충돌을 최대한 피해야합니다.
그런데 Java 8부터는 이 방식이 개선되었습니다. 처음에는 LinkedList로 사용하다가, 버킷에 있는 요소의 수가 많아지면 Red-Black Tree로 바꿉니다!
그러다가 다시 요소를 삭제하면서 수가 적어지면 LinkedList로 전환합니다. 기준이 되는 요소의 수는 아래와 같이 정의되어있습니다.
1
2
3
4
5
// 1개 버킷에 있는 요소가 8개를 이상이 되면, 그 버킷을 트리 구조로 바꾼다.
static final int TREEIFY_THRESHOLD = 8;
// 반대로 6개 이하로 줄면 LinkedList로 바꾼다.
static final int UNTREEIFY_THRESHOLD = 6;
해시 버킷의 개수는 동적으로 변한다.
앞서 버킷의 개수를 미리 정해두고 hashmap을 생성한다고 했습니다. Java의 HashMap에서는 따로 생성자에서 capacity를 지정하지 않으면, 16개로 사용합니다. (이 값은 자바 버전에 따라 다를 수 있습니다.)
버킷의 수는 반드시 2ⁿ이어야 합니다. (index 계산에서 언급한 최적화문제) 물론 capacity로 어떤 값을 넘기든 hashmap에서는 그 값에 가까운 2ⁿ을 찾아 버킷의 개수로 사용하니 우리는 편하게 사용할 수 있습니다.
계속 버킷을 16개만 사용하지는 않습니다. 버킷은 16개인데, 요소가 그 이상으로 많아지면 해시 충돌도 많아져서 성능이 더 나빠지겠죠.
HashMap에서는 요소의 개수가 특정 임계점을 넘어가면 버킷을 2배로 늘립니다. 이 수치는 버킷의 75%로 기본 설정되어있습니다. 물론 loadFactor로 바꿀 수 있습니다.
그래서 기본 값으로 hashmap을 만들면 버킷 16개의 75%인 12개가 임계점이 됩니다. 요소를 12개 이상 넣으면 버킷의 크기가 32개로 늘어납니다.
그런데 이 resize하는 과정이 꽤 무겁습니다. 자주 일어나면 성능상 안 좋습니다. 그래서 애초에 map에 요소를 많이 넣을 예정이라면 초기 버킷의 수를 많이 잡아야 성능상 유리합니다.
버킷의 개수가 2ⁿ개라 발생하는 문제
앞서 몇 번째 버킷에 Key에 매칭되는 value가 저장되어있는지 확인하는 방법을 설명드렸었습니다.
1
int actual_index = key.hashCode() % M;
이 방식으로 index를 구한다면, M이 소수여야 index의 분포가 고르게 나옵니다. 그런데 우리는 M을, 즉 버킷의 개수를 2ⁿ로 사용합니다. 그래서 버킷을 골고루 사용할 수 없게됩니다. 이 문제를 해결하기 위해서 보조 해시 함수를 사용합니다.
1
2
3
4
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
보조 해시 함수는 위와 같이 정의되어있습니다. (Java 8기준입니다.) 이 보조 해시 함수를 또 적용시켜서 좀 더 골고루 버킷을 사용할 수 있도록 합니다.
Java 8이전에는 더 복잡한 형태의 보조 해시 함수를 사용했습니다. 하지만 Java 8부터는 버킷에 트리를 도입하고, 대부분 hashCode가 잘 분포되도록 설계되어서 저렇게 간단한 형태로 개선되었다고 합니다.
HashMap vs HashTable
마지막으로 자주 언급되는 이 두 자료구조를 비교해보겠습니다.
HashMap
- Thread safe하지 않음. 직접 동기화시켜주어야 합니다.
- 보조 해시 함수가 있습니다. 그래서 해시 충돌이 비교적 덜 발생합니다.
- HashTable에 비해 빠른 성능.
- 지속적으로 개선되고 있습니다.
HashTable
- Thread safe 보장.
- 보조 해시 함수가 없고, 동기화 작업이 추가로 들어가므로 비교적 느립니다.
- 사실상 이제 업데이트는 안되고있고, 과거 자바 버전 호환성을 위해 존재합니다.
결론
HashMap은 Java에서 자주 사용되는 자료구조중 하나입니다. 사용하기 편리하지만, 잘못 사용하면 오히려 성능이 나빠질 수 있습니다. 그래서 HashMap을 사용할 때는 아래와 같은 사항들을 고려해봐야 합니다.
- HashMap에 많은 요소를 넣을 예정이라면, capacity를 미리 늘려놓자.
- hashCode 함수는 신중하게 작성해야한다. 잘못 작성하면 성능 하락을 넘어, 오작동을 일으킬 수 있다. 성능을 위해 버킷에 골고루 분포되도록 설계해야한다. IDE에서 제공해주는 hashCode 생성기를 사용하면 편리하다.
참고
- https://d2.naver.com/helloworld/831311
- 조슈아 블로크, 『Effective Java 3/E』, 프로그래밍 인사이트(2018), p63
- https://stackoverflow.com/questions/299304/why-does-javas-hashcode-in-string-use-31-as-a-multiplier